


#6 Why Avoid fallback in distributed systems?
In this article, the focus will be on how fallback strategies can cause more problems than they fix.

The Amazon Builders’ Library is a collection of articles that describe how Amazon develops, architects, release and operates technology. In Avoiding Fallback in Distributed Systems the risks of implementing fallbacks are discussed as well as the reasoning behind different strategies.
The following text consists of direct quotes from the original article, highlighting some points that caught my attention and that may motivate you to read the full original content:
This article covers fallback strategies and why we almost never use them at Amazon. The focus will be on how fallback strategies can cause more problems than they fix.
Fallback strategies must be planned in advance and used when necessary. Let's say an airport's display boards go out.
A contingency plan (such as humans writing flight information on whiteboards) must be in place to handle this situation because passengers still need to find their gates. The whiteboard fallback strategy is necessary but it’s riddled with problems
It is easy to develop fallback strategies that rarely trigger in production.
It might take years before even one customer's machine actually runs out of memory at just the right moment to trigger the specific line of code with the fallback
Fallback logic can also place unpredictable load on the system. Even simple common logic like writing an error message to a log with a stack trace is harmless on the surface, but if something changes suddenly to cause that error to occur at a high rate, a CPU-bound application might suddenly morph into an I/O-bound application.
A real-world major outage triggered by a fallback mechanism in the Amazon retail website illustrates all these problems The team also attempted to handle the case where the cache (a separate process) failed for some reason. In this scenario, the web servers reverted to querying the database directly.
In pseudo-code, we wrote something like this:
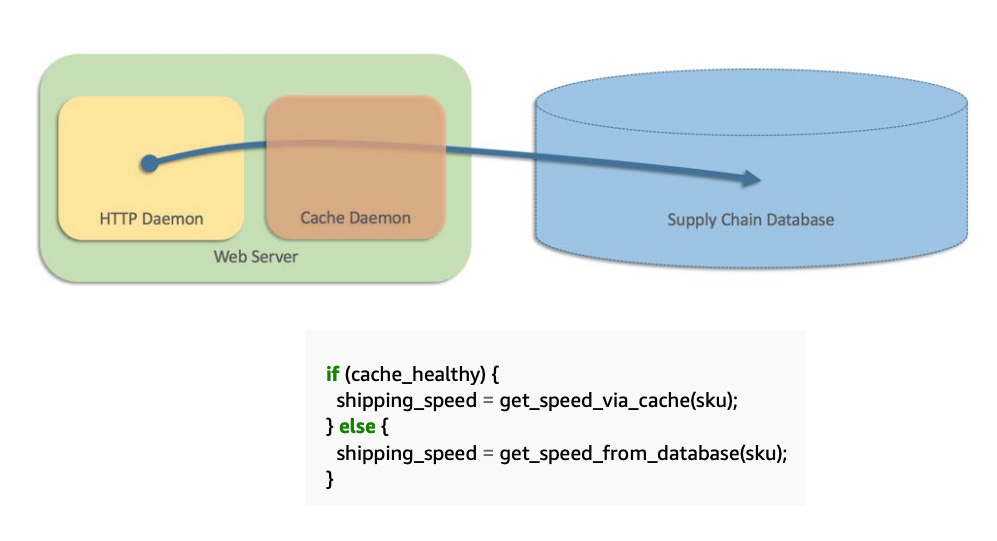
Image from https://aws.amazon.com/builders-library/avoiding-fallback-in-distributed-systems/ Falling back to direct database queries was an intuitive solution that did work for a number of months. But eventually, the caches all failed around the same time, which meant that every web server hit the database directly. This created enough load to completely lock up the database.
The entire website went down because all web server processes were blocked on the database.
This supply chain database was also critical for fulfillment centers, so the outage spread even further, and all fulfillment centers worldwide ground to a halt until the problem was fixed.
The fallback strategy itself amplified the problem and was worse than no fallback strategy at all. The fallback turned a partial website outage (not being able to display shipping speeds) into a full-site outage (no pages loaded at all) and took down the entire Amazon fulfillment network in the back end.
Improve the reliability of non-fallback cases.
A service can be much more available if the main (non-fallback) code is made more robust.
Let the caller handle errors
Reduce the number of moving parts when responding to requests. If, for example, a service needs data to fulfill a request, and that data is already present locally (it doesn’t need to be fetched), there is no need for a failover strategy.
Convert fallback into failover
One of the worst things about fallback is that it isn't exercised regularly and is likely to fail or increase the scope of impact when it triggers during an outage.
A service must run both the fallback and the non-fallback logic continuously. For example, a service might randomly choose between the fallback and non-fallback responses (when it gets both back) to make sure they're both working .
If fallback is essential in a system, we exercise it as often as possible in production, so that fallback behaves just as reliably and predictably as the primary mode of operating.
If you found this article useful, you might also enjoy reading about Metastable Failures in Distributed Systems:

That's all for this week.
I would also like to thank all the subscribers for supporting this initiative, and I hope it's as helpful to you as it is to me.
See you next week!
The Amazon Builders’ Library it is awesome. I really enjoy this article. Some company disagrees with this approach and add more complexity for the systems adding multiple fallbacks.
I think the more important thing it is to keep this:
> A service must run both the fallback and the non-fallback logic continuously
Sometimes the fallback it is only used when problems appears and another incident could happend because it.