


Metastable Failures in Distributed Systems
Some failure patterns in distributed systems that can give you quite a headache.

For me, the reading of Metastable Failures in Distributed Systems was quite interesting as it reminded me of some software incidents I've had to resolve. The main idea of the article is to present a concept called "Metastable Failure" and discuss some of them, like request retries, Look-aside Cache, Slow Error Handling and Link Imbalance.
The following text consists of direct quotes from the original article, highlighting some points that caught my attention and that may motivate you to read the full original content:
Metastable failures occur in open systems with an uncontrolled source of load where a trigger causes the system to enter a bad state that persists even when the trigger is removed.
When one of many potential triggers causes the system to enter the metastable state, a feedback loop sustains the failure, causing the system to remain in the failure state until a big enough corrective action is applied.

Metastable failures manifest themselves as black swan events; they are outliers because nothing in the past points to their possibility, have a severe impact, and are much easier to explain in hindsight than to predict.
Leaving a metastable failure state requires a strong corrective push, such as rebooting the system or dramatically reducing the load.
When investigating a metastable failure from production, we often find that the same root cause manifests earlier as latency outliers.
In fact, many production systems choose to run in the vulnerable state all the time because it has much higher efficiency than the stable state
The difference between the trigger and the sustaining effect makes it hard to discover the correct response, increasing the time to recovery.
Metastable failures manifest in a variety of ways, but the sustaining effect is almost always associated with exhaustion of some resource.
One of the most common failure-sustaining mechanisms is request retries. Retrying failed requests is widely used to mask transient issues. However, it also results in work amplification, which can lead to additional failures.
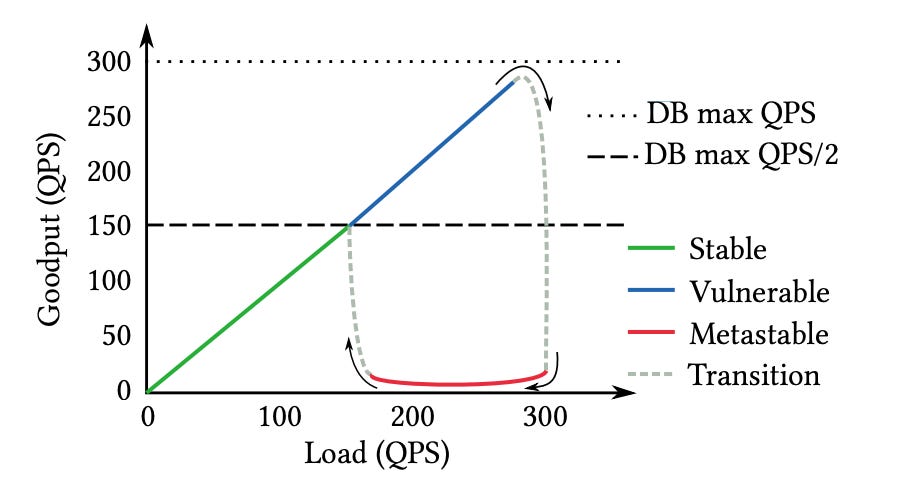
Caching can also make architectures vulnerable to sustained outages, especially look-aside caching … Assuming a cache with 90% hit-rate and the same database as before, the web application can now handle 3,000 QPS because only 1 out of 10 user requests result in a database query … however, loads above 300 QPS are in the vulnerable state since every request may need to contact the database in the worst case… In effect, losing a cache with a 90%hit-rate causes a 10×query amplification … The mechanisms described so far amplify the number of requests when the system encounters a failure.
Trigger vs. Root Cause: We consider the root cause of a metastable failure to be the sustaining feedback loop, rather than the trigger. There are many triggers that can lead to the same failure state, so addressing the sustaining effect is much more likely to prevent future outages.
You can watch the video below to familiarize yourself with the main concepts of the article.
That's all for this week.
I would also like to thank all the subscribers for supporting this initiative, and I hope it's as helpful to you as it is to me.
See you next week!
Excellent article! Very current topic.